
Static vs Dynamic Analysis and the Amusing Outcome
It all started with a malicious RTF document attached to an email and a request from reader Chris (thanks for your request and help!) to locate the embedded SWF object since it was believed to contain a hidden PE file.
The RTF document contained a 2012 exploit which is described here. The difference between the two documents is that this one contained a SWF file.
I proceeded to use oletools to search for SWF files using pyxswf.py. Nothing. I then used rtfobj.py to dump all the objects.

I looked through the files and no SWF header. I also used OfficeMalScanner's rtfscan and got the exact same objects and no SWF. I went back to each of the objects using a hex editor and I find the header...kind of.

The "FWS" header can be translated into hex as 0x465753 but in the file it shows up as "0x04657532". It's off by half-a-byte. I wrote a quick program that shifts the file by converting everything to hex, removing the first hex character at the beginning, padding the end with a null, then converting everything back into bytes.

Now I get the Flash file.

Chris suggested I use Didier Steven's rtfdump.py (with the latest fix -- version 0.5) which gets the job done.

Using JPEXS you can see the deobfuscation routine of the embedded binary data.

I created another program to do some ad hoc XOR'ing and I find that the binary blob is another Flash file. You can read this TrustWave article on Sundown EK and use their Python script.

This embedded SWF file is reusing an exploit from Magnitude EK. You can read about that exploit here btw. No sign of a PE file.

Let me go back to the large object I dumped earlier and try to find the PE file using static analysis. At the top, I notice that this is the same marker as the one identified in the SecureList blog post. Looks like the PE file is here but it's obfuscated.

I compare this file with the malware that gets dropped by the malicious RTF file and I can see that it lines up exactly and that the null bytes are left intact. Since nulls are present, I can rule out compression and modern encryption. That leaves shift and XOR as a possibility but since they ignored nulls, I can't easily get the key.

What I need to find is a large contiguous blob without any nulls. Near the bottom of the PE file I come across padding strings. There's other parts of the file I could use but this makes it quicker.

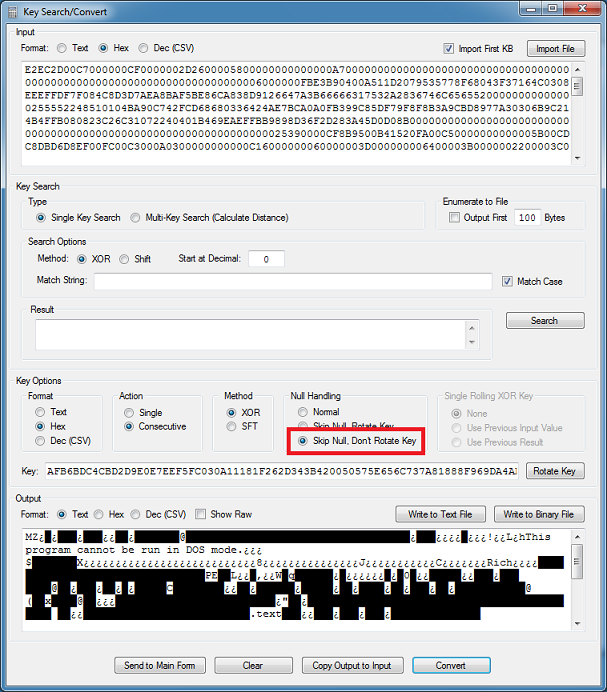
All I need to do is XOR the plaintext with the obfuscated portion and I can get the key. I use Converter's Key Search/Convert and paste the values in and I get the result.

Here's what the result looks like. It looks random but I'm hoping there's a repeating pattern here. That pattern would represent the XOR key.

Here's a trick I do to find a pattern. I simply change the dimensions of the Notepad window and watch the pattern emerge. There it is!

So the repeating value appears to be 256 bytes long and looks like this:
AFB6BDC4CBD2D9E0E7EEF5FC030A11181F262D343B420050575E656C737A81888F969DA4ABB2B9C0C7CED5DCE3EAF1F8FF060D141B222930373E454C535A61686F767D848B9299A0A7AEB5BCC3CAD1D8DFE6EDF4FB020910171E252C333A41484F565D646B727980878E959CA3AAB1B8BFC6CDD4DBE2E9F0F7FE050C131A21282F363D444B525960676E757C838A91989FA6ADB4BBC2C9D0D7DEE5ECF3FA01080F161D242B323940004E555C636A71787F868D949BA2A9B0B7BEC5CCD3DAE1E8EFF6FD040B121920272E353C434A51585F666D747B828990979EA5ACB3BAC1C8CFD6DDE4EBF2F900070E151C232A31383F464D545B626970777E858C939AA1A8Let me test this out with Converter. Ugh, so close!

After analyzing the results, I noticed that if a null character is present then it doesn't rotate the key for the next loop. So I add a new option to Converter...and it works! It works on the decoy document embedded in this object file as well.
Now I wanted to find the shellcode and verify this using dynamic analysis.
One way is to open the document with Word, dump the memory, then look for that marker. Here's the shellcode.

And here it is in the RTF document.

If you dissemble this, you find that the first part of the shellcode deobfuscates the second part. XOR'ing the second part with a value of 0xA6 reveals the PE decoding routine. I went ahead and XOR'd it then put everything together in IDA. But let me use a debugger instead...

Ah, it's not a 256-byte XOR key! You can see that the shellcode deobfuscates the PE file using XOR with a starting value of 0xA8 then incrementing it by 0x07. If there's a null byte then it skips that byte (and doesn't increment the value). How simple.
So at the end of all this, it turns out that the 256-byte XOR key found during static analysis is the same result I got dynamically albeit the long way to the solution. Very amusing!
Note: If you look at the XOR key above, you'll see that 0xAF + 7 = 0xB6 + 7 = 0xBD ...etc. And when you get to the end, 0xA8 + 7 = 0xAF.